I’m at the sixth codethecity, on day two of the History Jam. We’re working on creating a walk through 3D version of 1930’s Aberdeen using open data, Unity, and a lot of transcribing and cross referencing.
I’m working on pairing historic company data with the OSM (Open Street Map) building outlines that we’re using to create our 3D environment. This pairing is harder than it sounds. I’m starting with something relatively simple. Identify the occupants at ground level, using a combination of OSM data, feet and eyes, and Google Streetview.
Starting with RBOS outside M&S and working along to the St Nicholas graveyard should be easy. Shouldn’t it?.
Looking at Open Street Maps there there are six distinct buildings in this stretch.
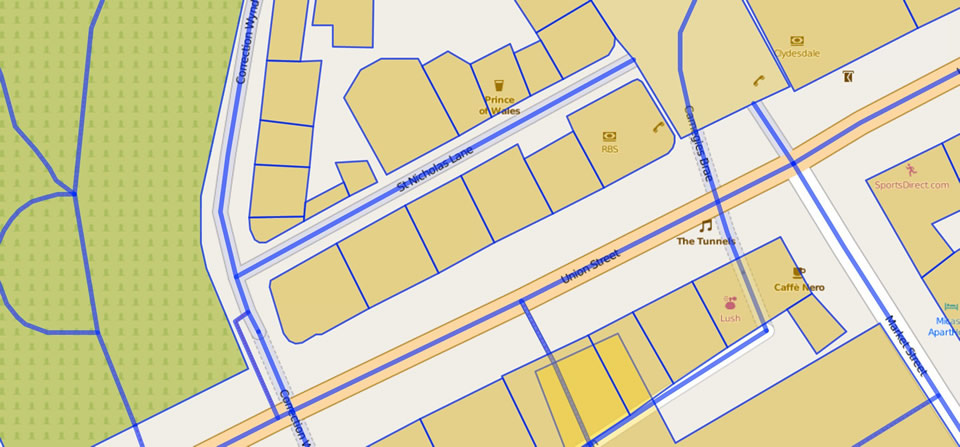
Looking at Google Maps it looks like we have five distinct buildings.

The StreetView level confirms this five building view if you ignore shop fronts and look at the physical buildings and roof lines.

Looking at the OS data through the Aberdeen City Council map viewer we see street numbers. We also see see – you guessed it – seven buildings.

Finally, looking at StreetView shopfronts we have eight individual shops at ground level.

We also know that the first address (labelled 1 above) is 104 Union Street, and that RBOS (labelled 8 above) is 78 Union Street.
Some Google searches, phone calls and directory checks gives us the following addresses:
- Vape Scotland, 104 Union Street
- Peterkins Solicitors, 100 Union Street
- O2, 98 Union Street
- Vodaphone, 92 Union Street
- McGowans Jewellers, 88 Union Street
- Timpson, 86 Union Street
- Casepoint, 82 Union Street
- RBOS, 78 Union Street
The Importance of our “Base Layer”
So clearly, we have five (or is it six, or seven?) ‘buildings’, and eight ‘shops’ at ground level. That kind of mismatch going to happen. Buildings change usage, they split, combine and generally change.
The challenge is that we need to associate an OSM Way ID with each shop in order to identify it within our visualisation. We’re creating 3D buildings based on the OSM outline data and then layering other info onto that. Things like historic photographs of the frontage, details of businesses that have traded from that address etc…
It’s because the OSM buildings don’t map to the building we see that this is causing some head scratching. The OSM ways don’t have addresses in most cases, they are simply outlines. Our challenge is mapping the eight occupants of the five real buildings to the six building outlines available in OSM.
So should we be starting with the OSM data?
I’m not so sure. The principle feels correct. Base our visualisation system around the best source of open data containing the buildings that we want to visualise, and add our new data to that.
We’re taking a lot of time to work around inconsistencies in the OSM data. Which inevitably introduces guesses. We’ve been mapping data to building outlines that might change / disappear.
PBKAC?
So we started out “pairing historic company data with the OSM (Open Street Map) building outlines”. That was where we went wrong.
Our answer, at least for now, is to avoid associating our data with building ways too early. If we simply store latt/long points for each address that we arrive at, and mash that with the building data later down the line, we can achieve everything we need to independently of any mismatch.
Using geolocated address nodes, rather than building ways,
If an address latt/long is within the way for a building, we can assume that the address is in the building. If that building way gets revised, or moved, or replaced at some point – we lose nothing – we still have out address latt/long.
It means we’re able to benefit from the OSM data, but we’re not tied to it, and we’re not limited by it.
It’s not as direct, but it’s much more robust. It also gives flexibility for the time travel aspects of the project – meaning that if a given street number moved for some reason, we can reflect this by date bounding our address nodes.

These are all the address nodes already in OSM for the area we want to cover. Far from comprehensive. We’re planning to push any new address locations we confirm as part of the project back into OSM to improve this. A comprehensive source of addresses would be invaluable.
You’ll be able to see the data we gathered during Codethecity 6 on github shortly, once we’ve finalised the licences and published.
